Paper2025.09.21
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning - Nature
요약
이 논문은 LLM의 추론 능력이 인간이 주석을 단 데모 없이 순수한 Reinforcement Learning(RL)을 통해 강화될 수 있음을 보여줍니다.
제안된 RL 프레임워크는 self-reflection, verification, dynamic strategy adaptation과 같은 고급 추론 패턴의 발전을 촉진합니다.
결과적으로, 훈련된 모델은 수학, 코딩 대회, STEM 분야와 같은 검증 가능한 작업에서 기존 supervised learning 방식보다 우수한 성능을 달성합니다.
상세 내용
이 논문은 인공지능(AI) 분야에서 오래 지속되어 온 난제인 일반적인 추론(reasoning) 문제를 다룹니다. 최근 Large Language Models (LLMs)와 Chain-of-Thought (CoT) 프롬프팅과 같은 발전은 기본적인 추론 작업에서 상당한 성공을 거두었지만, 이러한 성공은 광범위한 인간 주석이 달린(human-annotated) 시연 데이터에 크게 의존하며, 모델의 능력은 더 복잡한 문제에는 여전히 불충분하다는 한계가 있습니다.
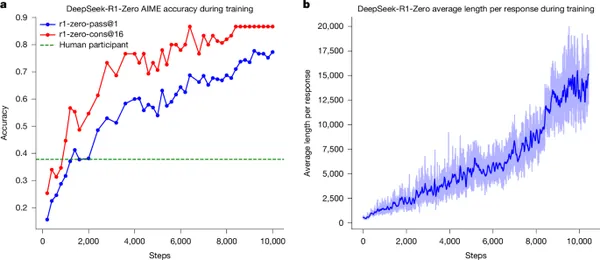
본 논문은 LLM의 추론 능력을 순수한 Reinforcement Learning (RL)을 통해 장려할 수 있음을 제시하며, 인간이 라벨링한 추론 궤적(human-labelled reasoning trajectories)의 필요성을 없앱니다. 제안된 RL 프레임워크는 Self-reflection, Verification, Dynamic Strategy Adaptation과 같은 고급 추론 패턴의 출현적인(emergent) 개발을 촉진합니다. 이는 사람이 직접 추론 과정을 주석으로 달거나 시범을 보이는 방식 대신, 모델이 스스로 환경과 상호작용하며 올바른 결과를 도출하는 과정을 보상받아 추론 능력을 학습하도록 하는 방법론을 채택합니다. 즉, 외부적으로 검증 가능한(verifiable) 최종 결과에 기반한 보상 신호를 사용하여 모델이 내부적으로 추론 과정을 개선하도록 유도하는 방식으로, 복잡한 추론 과정에 대한 명시적인 인간의 피드백 없이도 학습이 이루어집니다.
결과적으로, 이 방법으로 훈련된 DeepSeek-R1 모델은 수학, 코딩 대회 및 STEM 분야와 같이 검증 가능한 작업(verifiable tasks)에서 우수한 성능을 달성하며, 인간 시연 데이터에 대한 기존의 Supervised Learning을 통해 훈련된 모델들을 능가합니다. 또한, 이러한 대규모 모델에서 나타나는 출현적인 추론 패턴은 체계적으로 활용되어 더 작은 모델의 추론 능력을 안내하고 향상시키는 데 사용될 수 있습니다.
Web
Shared by Anonymous