How fast are Linux pipes anyway?
요약
vmsplice와 splice syscall을 사용하여 데이터 복사를 제거함으로써 파이프 성능을 30GiB/s 이상으로 크게 향상시켰습니다.상세 내용
write 및 read 시스템 콜을 사용하는 초기 3.5GiB/s의 처리량에서 시작하여 여러 단계의 개선을 통해 최대 20배 이상의 성능 향상을 목표로 합니다. 이 과정은 Linux perf 툴링을 사용하여 병목 현상을 식별하고, 커널 내부 동작을 이해하여 최적화 방안을 모색하는 방식으로 진행됩니다.초기 버전 및 write의 문제점:
초기 테스트 프로그램은 256KiB 크기의 버퍼를 write 시스템 콜을 사용하여 파이프에 쓰고, read 시스템 콜로 읽는 방식입니다. 이 설정에서 측정된 처리량은 3.7GiB/s로, 목표치인 FizzBuzz 프로그램의 36GiB/s에 크게 못 미칩니다. perf를 이용한 프로파일링 결과, 시간의 약 47%가 pipe_write 함수에서 소비되며, 특히 copy_page_from_iter와 __alloc_pages에서 많은 시간이 소요됨이 밝혀졌습니다.
파이프의 내부 구현:
Linux 파이프는 커널 내부에 구현된 링 버퍼(ring buffer) 형태로, struct pipe_inode_info 구조체로 관리됩니다. 이 링 버퍼는 struct pipe_buffer 타입의 배열로 구성되며, 각 pipe_buffer는 실제 데이터가 저장된 물리적 메모리 페이지(struct page)에 대한 참조를 가집니다. 기본적으로 16개의 슬롯을 가지며, 각 슬롯은 4KiB 페이지를 참조하므로 총 64KiB의 데이터를 저장할 수 있습니다. write 시스템 콜을 사용하면 사용자 공간의 데이터를 커널 공간의 파이프 버퍼로 복사하고, 다시 read 시스템 콜은 커널 공간의 데이터를 사용자 공간으로 복사합니다. 이러한 이중 복사(double copying), 4KiB 페이지 단위의 처리, 잦은 페이지 할당/해제, 그리고 파이프 락(pipe lock) 획득/해제로 인한 동기화 오버헤드가 초기 버전의 성능 저하의 주된 원인이었습니다.
splice 및 vmsplice 시스템 콜:
데이터 복사 오버헤드를 줄이기 위해 Linux는 splice와 vmsplice 시스템 콜을 제공합니다.
* splice: 파이프와 파일 디스크립터(예: 소켓, 파일) 간에 데이터를 복사 없이 이동시킵니다.
* vmsplice: 사용자 공간 메모리에서 파이프로 데이터를 복사 없이 이동시킵니다.
이들은 기존 메모리 페이지에 대한 참조를 파이프 링 버퍼에 추가하거나 제거하는 방식으로 작동하여 데이터 복사를 방지합니다.write를 vmsplice로 교체하고 256KiB 버퍼를 두 개의 128KiB 청크로 나누는 이중 버퍼링(double buffering) 방식을 적용한 결과, 처리량은 12.7GiB/s로 증가했습니다. 이어서 read를 splice로 교체하여 모든 복사를 제거하자 처리량은 32.8GiB/s로 크게 향상되었습니다.
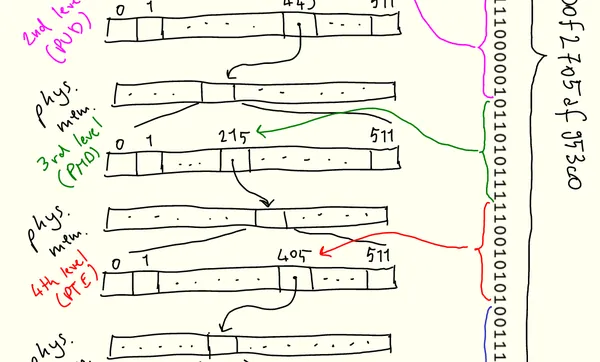
페이징(Paging) 및 get_user_pages_fast의 비용:vmsplice와 splice를 사용한 후 perf 분석 결과, 여전히 많은 시간이 파이프 락 획득(__mutex_lock)과 iov_iter_get_pages 함수에서 소비되고 있었습니다. iov_iter_get_pages는 vmsplice에 전달된 struct iovec (사용자 공간 가상 메모리 범위)를 파이프에 삽입할 struct page (물리적 메모리 페이지) 목록으로 변환하는 역할을 합니다.
이 과정은 운영체제의 가상 메모리(virtual memory) 관리와 밀접하게 관련됩니다. CPU는 가상 주소를 물리 주소로 변환하기 위해 페이지 테이블(page table)을 사용하며, 이 페이지 테이블은 4KiB 크기의 페이지 단위로 매핑을 관리합니다. iov_iter_get_pages는 내부적으로 get_user_pages_fast (GUP) 함수를 호출하여 페이지 테이블을 소프트웨어적으로 탐색하며, 사용자 공간의 가상 페이지에 해당하는 struct page 객체를 수집합니다. 128KiB의 데이터를 처리하기 위해서는 32개의 4KiB 페이지에 대해 이 과정을 반복해야 하며, 각 페이지에 대한 참조 카운트(reference count)를 증가시켜 페이지가 해제되지 않도록 합니다. 초기에 버퍼를 memset으로 초기화하는 것은 페이지 폴트(page fault)를 발생시켜 페이지 테이블 엔트리를 미리 생성함으로써 get_user_pages_fast의 "빠른 경로(fast path)"를 활성화하여 성능을 높이는 역할을 합니다.
거대 페이지(Huge Pages) 사용:get_user_pages_fast의 성능 병목을 해결하기 위해 거대 페이지(huge pages)가 도입됩니다. 거대 페이지는 4KiB보다 훨씬 큰 페이지 단위를 사용하므로(예: 2MiB 또는 1GiB), 페이지 테이블 탐색 횟수를 획기적으로 줄일 수 있습니다. 예를 들어, 2MiB 거대 페이지를 사용하면 128KiB 버퍼를 GUP가 처리할 필요 없이, 단일 2MiB 페이지에 대한 단일 struct page 참조로 처리할 수 있습니다. mmap 시스템 콜에 MAP_HUGETLB 플래그를 사용하여 거대 페이지를 할당하고, 파이프의 크기를 거대 페이지 크기에 맞게 조절했습니다. 이 변경으로 처리량은 37.0GiB/s로 향상되어 FizzBuzz 프로그램의 성능을 넘어섰습니다.
최종 최적화: Busy Looping:
거대 페이지를 적용한 후 perf 분석에서는 여전히 __mutex_lock과 schedule (파이프가 가득 찼을 때 대기하는 부분)에서 시간이 소비됨을 보여줍니다. 이는 파이프가 가득 찼을 때 vmsplice가 스케줄러에 의해 블록(block)되고, 파이프가 비워질 때까지 대기한 후 다시 스케줄링되는 과정에서 발생하는 오버헤드입니다. 이 오버헤드를 줄이기 위해, poll 시스템 콜을 사용하여 파이프가 쓸 준비가 될 때까지 기다리는 대신, SPLICE_F_NONBLOCK 플래그를 vmsplice에 전달하고 EAGAIN 오류가 반환될 때까지 바쁜 대기(busy looping)를 수행하도록 변경했습니다. 이 방식은 CPU를 낭비하지만, 컨텍스트 스위치(context switch) 오버헤드를 제거하여 처리량을 45.3GiB/s로 더욱 향상시켰습니다. (참고: 이 최적화는 실제 애플리케이션에서는 CPU 사용률 증가로 인해 일반적으로 권장되지 않습니다.)
결론:
이 논문은 Linux 파이프의 성능 병목 현상을 체계적으로 분석하고, write/read 시스템 콜의 복사 오버헤드, 페이지 테이블 탐색 비용, 그리고 스케줄링 오버헤드를 식별했습니다. splice, vmsplice를 통한 제로-카피(zero-copy), 거대 페이지(huge pages)를 통한 페이지 테이블 탐색 최적화, 그리고 busy looping을 통한 스케줄링 오버헤드 제거를 통해 파이프 처리량을 3.5GiB/s에서 45.3GiB/s로 약 13배 이상 향상시키는 과정을 상세히 보여주었습니다. 이는 커널 내부 메커니즘에 대한 깊은 이해가 고성능 I/O 애플리케이션 개발에 얼마나 중요한지를 잘 보여줍니다.